
从大作业说起
上大学的时候,相信很多学软件工程的同学常会有个大作业要求做一个图书管理系统或人事管理系统,本质上就是设计一个数据库存储系统。我们以图书管理系统为例,假设需要存储的字段有id,name(书名),author(作者),查询的需求为根据id去获取图书的信息。
最简单的做法,以id为key,剩下的作为value,在内存中构建一个hashtable,或者R/B tree 比如c++ stl里的map,全内存存储,这是在数据量不大的情况下。内存的随机读写的性能是非常好的,1s中大约能查询1千万次。
接下来考虑数据量增大的情况,当数据已经在内存中存不下了,那就得靠存磁盘了,通常的考虑是每条记录按顺序存下来,放到一个文件里去,内存中仍然有一个hashtable,以id为key,value为对应数据记录在文件中的offset(偏移量)。这种做法的特点是数据本身是序列化存在磁盘上的,但索引是存内存中的,当要查询的时候,首先在内存中根据id找到对应磁盘文件的offset,再在文件中fseek定位并读出数据
现在我们来分析下目前这个存储系统的性能是怎样的,通常对一个存储系统来说,性能评价指标是IOPS(每秒做多少次IO),以SATA磁盘为例,它的寻道时间平均是在10ms,我们每次查询一条数据,需要一次磁盘的寻道操作,也就是说如果忽略掉磁盘的缓存及本身电梯算法带来的优化,1s中只能做100次这样的查询
再进一步考虑,假设数据量大到索引也不能够全内存了该怎么处理?这里假设id是有序的,就可以考虑用B+ tree来存,B+ tree有三种节点,根节点、非叶子节点、叶子节点,根据B+ tree的特点,非叶子节点的数量一定是比叶子节点的数量少的多,这些节点信息全部是存在磁盘上的,而在实际应用中非叶子节点是会被大量缓存住的,故在分析性能时可以将非叶子节点当做是存储在内存中来分析。
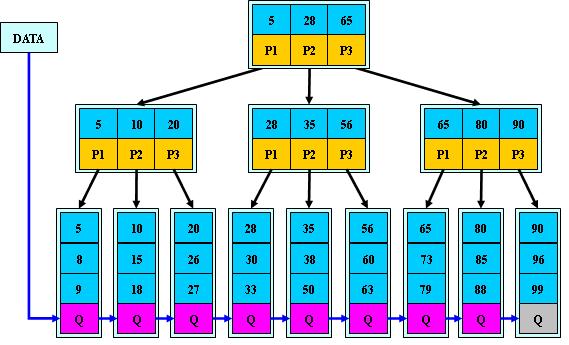
在这种情况下,单个查询是如何进行的呢?从根节点开始, 一层层的找到叶子节点中的数据。非叶子节点的索引信息假设都从内存缓存中读取,相对于磁盘IO来讲,时间可以忽略不计。读取叶子节点的索引值有1次fseek,同时读取数据内容还需要1次fseek。也就是说每次查询要有2次磁盘寻道,qps下降到50;
假设有一个范围查询的需求,需要查询id从50 - 100范围的记录。 50个id,要fseek100次。也就是说这个查询要1s才能返回,而且这个时间是完全落在磁盘的随机IO上,很难从硬件或提高并发来做优化,性能是非常糟糕的。在这里很重要的一个思想,是要想办法把所有的随机读随机写都转成顺序读和顺序写。磁盘本身的顺序读写是非常好的,像SATA磁盘每秒可以写50M。那可以考虑数据按照page组织起来,让数据在page之间按id是有序的,这种情况下,我只需要fseek找50所在的偏移量,接下来顺序的读一批,10ms读索引,10ms读50所在的page的数据。读都是以page为单位的。
这里如果是全局有序的,而不按page会有什么问题?如果严格有序就会很惨,每次插入新的元素,都会有节点的分裂,会有更多的IO操作。按page的话,page可能没有写满,剩下的一些空间就是用来插这个范围之内的可能写入的其他id。这种方式可以提高一些插入的性能。
作为一个软件工程的作业,做到这里已经算是非常非常优秀的成果了。对于存储系统而言,接下来还要考虑是怎么访问的,也就是函数API或者叫存储系统的界面。数据库系统提供的访问界面是SQL,事实上我们也可以不通过SQL来访问,比如innodb,能把mysql上面一层去掉,通过HandlerSocket插件提供的API接口,进而不通过SQL去访问它。
ACID
数据库的主要功能是保证ACID。我们前面的访问都只是单个的访问,那么假设我们有两个线程在同时读写,那如何让这两个线程看起来像是独占这个存储系统一样,这就是数据库的隔离性(I)。I是通过锁来保证的,一个操作会锁住的内容比想象的要多得多。A是原子性。数据库保证我们的数据安全,要么是没有做的状态,要么是完成的状态,不应该有中间的状态,即使掉电。C是一致性,系统从一个一致的状态转换到另一个一致的状态,分为强一致性、弱一致性和最终一致性,在分布式存储系统受通信延迟,系统负载等影响,要实现不同的一致性会有不同的挑战,根据具体的业务会做一些取舍;D持久性,数据要持久化存储,同时还要有日志。
KV的一些NoSQL存储系统,实际上是放宽了ACID的条件约束,来实现更高的性能,比如不支持事务的并发,只支持单条的事务,还有比如一致性,写下去不一定成功,只有当merge的时候才能成功。一般说数据库性能差,主要是因为数据库为了实现ACID、transaction等功能牺牲了性能。
拿mysql来看数据库系统有哪些模块

比较重要的几个模块:
- 数据库客户端,通常来说会做成一个lib,应用端可以通过这个lib来与数据库交互
- 连接池,验证/线程重用/最大连接数限制
- SQL解析器,SQL parser
- 优化器,根据解析后的SQL的一些条件,决定走哪一个执行路径。使用哪个索引得到需要的数据。同一条SQL语句在不同的执行路径下千差万别,数据库最最重要和复杂的就是优化器,像商业数据库相比开源数据库最大的优势就是优化器会做的更专业,也会存在非常多的专利
- 缓存,因为磁盘的随机IO惨不忍睹,所以通常要把查询的结果缓存起来
对于缓存来讲,这次读完下次不再需要了的,是完全没必要缓存。而像数据库系统的一个特点是现在要读的通常是刚读过不久的,也就是所谓的时效性的一个热点,这种情况下读缓存和写缓存会起到非常大的作用。缓存利用的好的话,所有查询都落到内存中,qps可能好几千上万,如果不幸的话全部落在磁盘上的话,qps也就只有一两百了。
MySQL 5.1以后是插件式的一个系统,数据是怎么结构化存储的、索引是怎么组织的、以及加锁等都是通过接口的方式提供出来,方便做二次开发。只要实现handler.h里的这些接口,就可以做一个MySQL的存储引擎,没有想象的那么复杂。MySQL也自带innodb、myISAM等存储引擎,悲剧在于没有一个存储引擎特别好用。 - 存储引擎下面是跟文件系统打交道。数据、索引、日志
数据库本身是如何做结构化存储
单条记录的结构
对于一条数据记录,有些字段可以为空,有些有default值,有些是可以变长的。通常来讲会在记录头记录一个总长度,后面是一些pointer,比如有指向后面哪些字段是可以为空并且为空的等等,之后是根据表结构的定义,一个字段一个字段挨着存储。页的结构
将每个记录的指针按插入的顺序串起来,作为page里的数据。注意这些数据并不是按key有序的而是按插入顺序。
假设在往page里写一半的时候掉电了,重启之后,怎么判断这个page是好的还是坏的?通常的做法是在page的首尾各加2byte放一个cookie,要么为10或者01,好的page首尾的cookie是一致的,在开始写的时候,头部如果是10就改为01,在写完的时候把尾部的10也改为01。就是说如果读上来一个page,头部是10,尾部是01,那这个page的数据就是坏的。
那page如果坏掉了,就要从日志里恢复,所以page里一定还要记一个跟日志相关联的信息叫LSN。
日志里要存的信息有 UNDO(做之前)/REDO(做之后),以及这个操作是在哪个page,还有LSN。单机的话可以拿相对于日志文件头的偏移量作为LSN,也可以用时间戳,集群的话就需要一个中央的授时。
在重启后,读出最后一个page的LSN,并找到对应的日志,通过之后的日志可以知道丢了多少条更新可以进行重做,或者事务的回滚表和索引的结构
索引是用B+ tree的结构,节点里一般存上page id + record id
innodb的实现是区分主键索引和辅助索引。对于主键索引数据本身作为索引的leaf page。这样做按主键做范围查询,性能是非常好的。而对于辅助索引里存放的是主键索引所在的节点地址。
如果查询是命中的辅助索引,就会先找到这个辅助索引的leaf page再走一遍主键索引。所以innodb命中主键索引和辅助索引即使是单条查询性能也是不一样的。
数据库的四种访问模式,怎么从数据库里找到一条数据
Table Scan
在没有where的时候,或者where条件没有命中任何索引,优化器就什么都不能做了,只能全表扫描。对于大表来说,一个SQL全表扫描跑个几天都是常见的。Index Only
有个联合索引 id, name。查询为select name from table where id = xx 在这种情况下,只需要读到这个索引,就可以直接返回了,这是最好的一种情况。Index Match
最常见到的,通过id命中index,通过index打开数据文件,将数据内容读取出来返回。Index Scan
假设有一个id和name的联合索引,查询是select id from table where name >xxx,这个索引是用不了的。这种时候数据库优化器会发现只要Index Scan就能满足查询要求,故不用Table Scan。
聚集索引与非聚集索引
聚集索引是指数据是按照索引排序的,对于Innodb毫无疑问主键索引就是聚集索引。为什么要按照索引对数据排序,这个主要是在范围查询的时候,按照主键顺序查询的时候性能是很好的。
总结一下使用数据库系统影响性能的关键
索引的设计,索引设计的好,直接会是Index Only或者Index Match的,设计的不好就得是Table Scan全表扫描了
聚集非聚集索引,对于范围查询是至关重要的
数据库SQL性能优化思路
- 尽量走索引
- 避免随机IO,不多解释了
- Innodb的Insert buffer对写性能的优化
随机写主键索引可能需要1到2次IO,辅助索引也可能是1到2次IO,这么多次随机IO导致写入性能是非常低下的。在这里假设所有索引不需要保证唯一性,顺序将数据先写入Insert buffer page,在空闲的时候再把Insert buffer里的数据merge写到最终需要的地方,慢慢去做随机IO。这种在写入高峰期的时候能起到明显的性能提升。